

Note_Udacity: Intro to ML with Tensor Flow – Scholarship Program Nanodegree Program
Calculating Information Gain of Different Split Criteria:
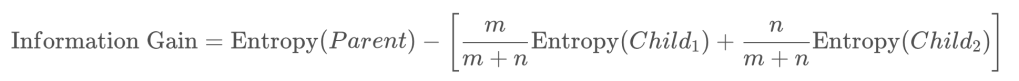
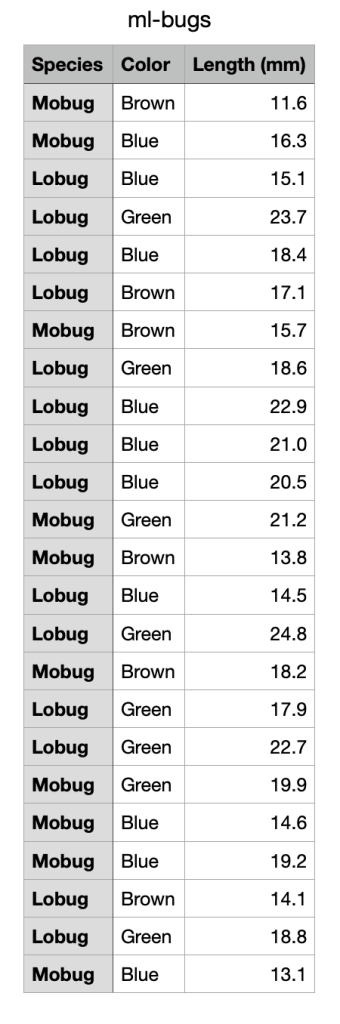
The data lists as below, consisting of twenty-four made-up insects measured on their length and color. Which of the following splitting criteria provides the most information gain for discriminating Mobugs from Lobugs?
- Color = Brown
- Color = Blue
- Color = Green
- Length < 17 mm
- Length < 20 mm
Here is my solution:
The output looks like this:
Color = Brown : 0.062 Color = Blue : 0.001 Color = Green : 0.043 Length < 17 : 0.113 Length < 20 : 0.101
We gain more information from the splitting criteria- Length < 17.
import numpy as np
import pandas as pd
df = pd.read_csv('ml-bugs.csv')
df.head()
def count_item(df, title, item):
number = df[df[title] == item].shape[0]
return number
def get_species_entropy(df):
number_lobug = count_item(df, 'Species', 'Lobug')
number_mobug = count_item(df, 'Species', 'Mobug')
total_bugs = number_lobug + number_mobug
num_bugs_list = [number_lobug, number_mobug]
props = np.array([i/ total_bugs for i in num_bugs_list])
logs = np.log2(props)
entropy = np.sum(-props * logs)
return entropy
def get_info_gain(item):
sub = df[item].copy()
not_sub = df[~item].copy()
number_sub = sub.shape[0]
number_not_sub = not_sub.shape[0]
total = number_sub + number_not_sub
sub_weight = number_sub / total
not_sub_weight = number_not_sub / total
sub_entropy = get_species_entropy(sub)
not_sub_entropy = get_species_entropy(not_sub)
parent_entropy = get_species_entropy(df)
return parent_entropy - (sub_weight * sub_entropy + \
not_sub_weight * not_sub_entropy)
for item, string in [(df['Color'] == 'Brown', 'Color = Brown'),
(df['Color'] == 'Blue', 'Color = Blue'),
(df['Color'] == 'Green', 'Color = Green'),
(df['Length (mm)'] < 17, 'Length < 17'),
(df['Length (mm)'] < 20, 'Length < 20')]:
info_gain = get_info_gain(item)
print(string,':','{:.3f}'.format(info_gain))
Reference:
